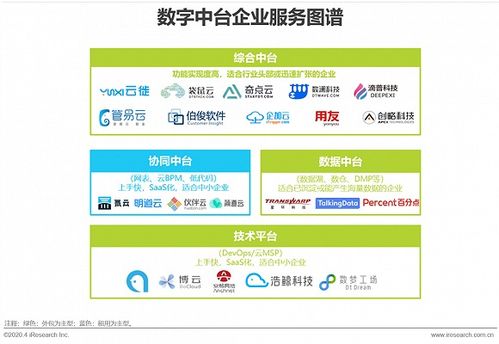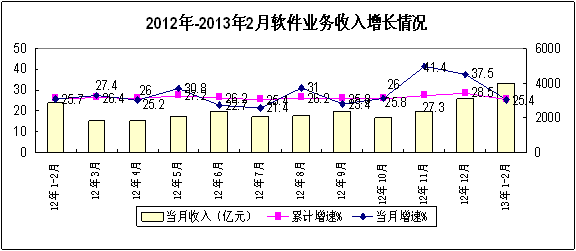
備受關(guān)注的開源項目vLLM正式發(fā)布其核心論文,該項目在GitHub上已獲得超過6.7k星標(biāo),成為大語言模型(LLM)推理部署領(lǐng)域的重要里程碑。vLLM通過創(chuàng)新的內(nèi)存管理和調(diào)度算法,顯著提升了LLM服務(wù)的吞吐量和效率,為開發(fā)者、研究人員和企業(yè)提供了前所未有的低成本、高性能LLM部署解決方案。
技術(shù)突破:PagedAttention與連續(xù)批處理
vLLM的核心創(chuàng)新在于其提出的PagedAttention機制,靈感來源于操作系統(tǒng)的虛擬內(nèi)存分頁管理。傳統(tǒng)LLM推理過程中,KV緩存(Key-Value Cache)的內(nèi)存分配常常導(dǎo)致碎片化和低效利用,尤其在處理可變長度序列時。vLLM將KV緩存劃分為固定大小的“塊”,實現(xiàn)動態(tài)分配和共享,大幅減少內(nèi)存浪費,使系統(tǒng)能夠同時處理更多請求。
配合連續(xù)批處理技術(shù),vLLM能夠?qū)⒉煌埱蟮男蛄懈咝ЫM織在批次中,即使這些請求的輸入和輸出長度差異很大。這種設(shè)計不僅降低了延遲,還提升了GPU利用率,使得單臺服務(wù)器能夠承載比傳統(tǒng)方案多出數(shù)倍的并發(fā)請求。
應(yīng)用場景:數(shù)據(jù)處理與存儲服務(wù)的深度融合
vLLM的論文特別強調(diào)了其在數(shù)據(jù)處理和存儲服務(wù)領(lǐng)域的應(yīng)用潛力。傳統(tǒng)數(shù)據(jù)處理流水線往往需要頻繁調(diào)用LLM進行文本分析、分類、摘要或?qū)嶓w識別,但高延遲和成本限制了實時處理能力。vLLM的高吞吐特性使得以下場景成為可能:
- 實時數(shù)據(jù)流分析:對日志、社交媒體流或交易記錄進行即時情感分析、異常檢測,無需預(yù)先批處理。
- 智能文檔存儲與檢索:在存儲系統(tǒng)中集成LLM,自動生成文檔摘要、提取關(guān)鍵詞,提升檢索效率和用戶體驗。
- 低成本多租戶服務(wù):云服務(wù)提供商可以基于vLLM構(gòu)建共享的LLM推理平臺,為多個客戶提供穩(wěn)定、經(jīng)濟的模型服務(wù),同時保持隔離性。
- 邊緣計算部署:在資源受限的邊緣設(shè)備上,vLLM的高效內(nèi)存管理使得部署中型LLM成為可能,支持本地化實時處理。
部署簡易性與生態(tài)兼容
論文展示了vLLM與流行深度學(xué)習(xí)框架(如Hugging Face Transformers)的無縫集成,開發(fā)者只需少量代碼修改即可將現(xiàn)有模型遷移到vLLM引擎上。vLLM支持多種服務(wù)協(xié)議,包括OpenAI兼容的API接口,方便現(xiàn)有應(yīng)用快速接入。
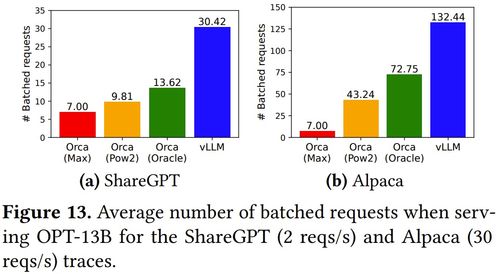
對于希望自建LLM服務(wù)的中小團隊或個人研究者而言,vLLM大幅降低了硬件門檻和運維復(fù)雜度。實驗數(shù)據(jù)顯示,在相同硬件配置下,vLLM相比優(yōu)化前的推理系統(tǒng)可實現(xiàn)高達24倍的吞吐量提升,同時保持更低的延遲和更穩(wěn)定的服務(wù)質(zhì)量。
未來展望
隨著LLM應(yīng)用場景的不斷拓展,高效推理框架將成為AI基礎(chǔ)設(shè)施的關(guān)鍵組成部分。vLLM的開源論文不僅提供了技術(shù)細節(jié),也標(biāo)志著社區(qū)驅(qū)動創(chuàng)新的力量。結(jié)合量化、蒸餾等模型壓縮技術(shù),vLLM有望進一步推動LLM服務(wù)的普及,真正實現(xiàn)“讓每個人都能輕松快速低成本地部署LLM服務(wù)”的愿景,為數(shù)據(jù)處理、內(nèi)容生成、智能交互等領(lǐng)域的應(yīng)用注入新動力。