引言:云原生時代的基石
在數字化轉型浪潮中,應用開發與部署模式正經歷深刻變革。容器技術,特別是以Docker為代表的容器化方案,通過將應用及其依賴封裝成輕量級、可移植的單元,解決了“在我機器上能運行”的經典難題。當企業試圖在生產環境中大規模部署和管理成百上千的容器時,挑戰接踵而至:如何調度?如何擴展?如何確保高可用與自愈?此時,容器編排 應運而生,而Kubernetes 無疑是這個領域的王者與事實標準。
一、Kubernetes:容器編排的領航者
Kubernetes(常簡稱為K8s)是一個開源的容器編排平臺,起源于Google內部的Borg系統。它提供了一個強大的框架,用于自動化部署、擴展和管理容器化應用。其核心價值在于:
- 聲明式配置與自動化:用戶通過YAML或JSON文件聲明應用的期望狀態(如運行3個副本),K8s的控制平面會持續工作,確保實際狀態與期望狀態一致,自動處理節點故障、容器重啟等。
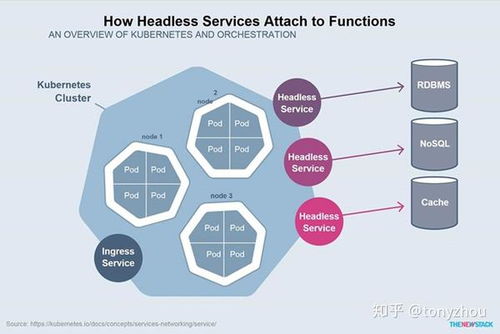
- 服務發現與負載均衡:K8s可以自動為容器組(Pod)分配IP地址和DNS名稱,并通過Service等抽象實現流量的負載均衡,使微服務間的通信變得簡單可靠。
- 彈性伸縮:支持根據CPU、內存使用率或自定義指標進行水平自動伸縮,從容應對流量高峰。
- 自我修復:自動重啟故障容器、重新調度失效節點上的容器、替換不健康的容器,保障應用持續可用。
二、Kubernetes在數據處理與存儲服務中的關鍵角色
數據處理與存儲是現代應用的“心臟”,其需求包括持久化、高性能、可擴展性和高可用。Kubernetes通過一系列原生概念和擴展機制,為這些需求提供了優雅的解決方案。
1. 數據持久化:Volume與PersistentVolume
容器本身是臨時的,其文件系統生命周期與容器相同。Kubernetes通過 Volume(卷) 抽象解決了數據持久化問題。
- 基礎Volume:支持多種類型,如hostPath(節點本地目錄)、NFS、云存儲等,允許容器訪問外部存儲。
- PersistentVolume (PV) / PersistentVolumeClaim (PVC):這是更高級的存儲管理模型。管理員預先配置存儲資源池(PV),用戶通過PVC聲明存儲需求(如大小、訪問模式)。K8s自動將PVC與合適的PV綁定,實現了存儲的“按需供給”,與應用部署解耦。這對于數據庫、文件服務器等有狀態應用至關重要。
2. 有狀態應用編排:StatefulSet
Deployment適用于無狀態應用,但對于MySQL、Kafka、Elasticsearch等有狀態服務,需要穩定的網絡標識、有序的部署/擴展和持久的存儲。StatefulSet 正是為此設計:
- 穩定的Pod標識:每個Pod擁有一個永久的、按序的標識符(如
kafka-0,kafka-1),即使重啟或重新調度,其主機名和存儲卷保持不變。 - 有序部署與管理:Pod按順序創建、擴展或刪除,確保集群化服務(如主從數據庫)的啟動順序和穩定性。
- 與PVC的強關聯:每個Pod實例可以擁有自己專用的PVC,確保數據與實例一一對應,避免混亂。
3. 數據處理工作流與批處理:Job與CronJob
數據處理不僅限于長期運行的服務,還包括定時任務和批處理作業。Kubernetes提供了:
- Job:創建一個或多個Pod,并確保指定數量的Pod成功終止。用于運行一次性任務,如數據遷移、報表生成。
- CronJob:基于時間表(Cron表達式)周期性運行Job,完美支持數據備份、定期ETL(提取、轉換、加載)等場景。
4. 與生態系統的集成
Kubernetes的強大還體現在其蓬勃發展的生態系統上,特別是在數據處理與存儲領域:
- 云原生存儲方案:如Rook(提供Ceph、EdgeFS等存儲系統的K8s原生編排)、Longhorn(輕量級、易用的分布式塊存儲)、OpenEBS(容器原生存儲)。
- 大數據與流處理框架:Apache Spark、Flink、Kafka等主流框架都提供了Kubernetes原生支持或Operator,可以直接在K8s集群上運行,享受統一的資源調度和管理便利。
- 數據庫Operator:通過Operator模式(一種K8s的擴展機制),可以像管理原生K8s資源一樣管理復雜的有狀態應用。例如,PostgreSQL的Crunchy Data Operator、MySQL的Oracle Operator,它們自動化了數據庫的部署、備份、恢復、升級等運維操作。
三、總體架構與工作流程
一個典型的在Kubernetes上運行數據處理服務的工作流程如下:
- 定義存儲:管理員創建存儲類(StorageClass),定義動態供給的存儲類型。用戶通過PVC申請持久化存儲。
- 部署有狀態服務:使用StatefulSet定義數據庫或消息隊列(如MySQL集群),每個Pod實例自動關聯一個獨立的PVC。
- 部署數據處理應用:使用Deployment部署微服務或無狀態數據處理應用(如API服務、轉換服務)。它們通過K8s Service訪問有狀態服務。
- 運行批處理任務:使用Job或CronJob運行數據分析腳本或定時任務,任務可以掛載PVC或ConfigMap(用于配置)來讀取和寫入數據。
- 監控與伸縮:利用Horizontal Pod Autoscaler根據數據處理負載自動調整應用實例數,并通過Prometheus等監控工具觀察整個數據流水線的健康狀況。
###
Kubernetes不僅是一個容器編排器,更是一個強大的分布式系統平臺。它將計算、網絡和存儲的抽象提升到一個新的高度,使得構建和管理復雜、彈性的數據處理與存儲服務變得前所未有的標準化和自動化。通過將存儲生命周期與容器生命周期解耦,并通過StatefulSet、Operator等模式為有狀態應用提供一流支持,Kubernetes正成為云原生時代數據基礎設施的堅實底座。擁抱Kubernetes,意味著擁抱更高效、更可靠、更敏捷的數據驅動未來。